
Datenreplikation
Was ist Datenreplizierung?
Als Datenreplizierung bezeichnet man den Prozess der Aktualisierung von Daten in einem Ausgangssystem und der anschließenden Synchronisierung dieser Daten in einem Zielsystem. Der Mechanismus der Datenreplizierung ermöglicht es, Content im Hintergrund und ohne Störungen im Live-System zu entwickeln und zu pflegen.
Datenreplizierung betrifft sowohl Daten in Datenbanken (z. B. Katalog-, Produkt- oder Benutzerdaten) als auch Daten im Dateisystem von Intershop Commerce Management (z. B. Bilder oder Produktanlagen).
Gleichzeitige Massendatenoperationen und individuell ausgelöste "Einzel-Objekt"-Operationen können inkonsistente Daten produzieren. Intershop Commerce Management verfügt über einen speziellen Objekt-Sperre-Mechanismus, um gleichzeitige Veränderungen derselben Daten zu verhindern. Für den Fall, dass ein Benutzer beabsichtigt, ein Objekt zu ändern, das bereits durch einen anderen Prozess gesperrt ist, zeigt Intershop Commerce Management eine Warnung und bietet, abhängig von der Operation, die folgenden Optionen an:
-
Die Sperre aufheben, wodurch der "aufrufende" Prozess Priorität erhält und durchgeführt werden kann,
-
Eine bestimmte Zeit warten. Der "aufrufende" Prozess wartet eine festgelegte Zeit darauf, dass die Sperre aufgehoben wird, um danach ausgeführt zu werden. Bei einem Timeout schlägt der Prozess fehl.
-
Fehlschlagen, wobei der "aufrufende" Prozess sofort beendet wird.
Die Datenreplizierung umfasst zwei wesentliche Schritte: das Festlegen von Replikationsaufgaben und das Ausführen dieser Aufgaben als Replikationsprozesse. Beide Schritte sind nachfolgend näher beschrieben.
Replikationsaufgaben
Replikationsaufgaben bestimmen den zu replizierenden Content. Sie werden vom verantwortlichen Datenreplizierungsverwalter für jeden Channel einzeln in Intershop Commerce Management definiert. Beispiel: Der Datenreplizierungsverwalter des Beispiel-Channels "inTRONICS" kann Replikationsaufgaben für diesen Channel definieren.
Für jede Replikationsaufgabe definiert der Datenreplizierungsverwalter
-
Startdatum
Das Startdatum legt die frühestmögliche Zeit fest, zu der eine Replikationsaufgabe ausgeführt werden kann.
-
Replikationsgruppen
Jeder Replikationsaufgabe werden eine oder mehrere Replikationsgruppen zugewiesen. Replikationsgruppen identifizieren den zu replizierenden Content. Jede Replikationsgruppe bezieht sich auf eine bestimmte Content-Domäne. Beispiel: Die Replikationsgruppe "Organisation" umfasst das Organisationsprofil, die Abteilungen, die Benutzer und Rollen sowie alle für die Organisation definierten Einstellungen.
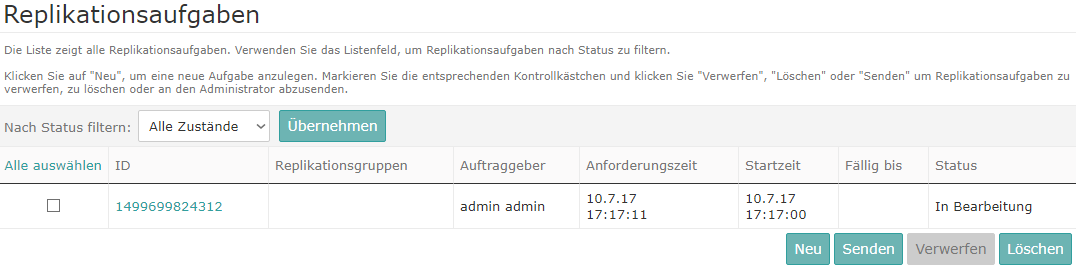
Informationen zu Replikationsaufgaben, siehe Verwaltung von Replikationsaufgaben.
Replikationsprozesse
Nachdem die Replikationsaufgaben definiert sind, werden sie an den Systemadministrator zur Ausführung übermittelt. Zur Ausführung von Replikationsaufgaben definiert der Systemadministrator Replikationsprozesse in Intershop Organization Management.
Für jeden Replikationsprozess definiert der zentrale Administrator:
-
Zielsystem
Ein Ausgangssystem kann mit mehreren Zielsystemen verbunden sein. Für jeden Replikationsprozess kann jedoch nur jeweils ein Zielsystem (oder Cluster) ausgewählt werden.
-
Replikationsaufgaben
Jeder Replikationsprozess führt eine oder mehrere Replikationsaufgaben aus, je nachdem, wie sie der jeweilige Datenreplizierungsverwalter übermittelt hat. Nur solche Replikationsaufgaben, deren Startzeit erreicht ist, können von einem Replikationsprozess erfasst werden.
-
Aktivierungsregeln
Replikationsprozesse können manuell oder als geplanter Job zu einer bestimmten Zeit gestartet werden.
-
Replikationstyp
Der Replikationstyp bestimmt, ob ein Replikationsprozess nur die Content-Übertragung, die Content-Publizierung oder beides beinhaltet. Für spezielle Aufgaben oder zum Aufheben eines Replikationsprozesses mit Content-Publizierung sind weitere Replikationstypen verfügbar.